
Google Research just dropped something interesting at ICLR this year: ReasoningBank. It’s a memory framework for AI agents that tries to solve a problem I’ve been grumbling about for a while — the fact that most agents treat every new task like they’ve never seen one before.
If you’ve worked with any of these LLM-based agents for web browsing or coding tasks, you’ve seen the pattern. They’ll nail a task one minute, then trip over the exact same kind of obstacle ten minutes later. No learning curve. No “oh, I’ve been here before.” Just the same mistakes on repeat.

Memory content comparison: existing strategies and ReasoningBank.
The core problem with existing agent memory
Most memory systems for agents fall into two camps, and neither works well enough.
First camp: exhaustive trajectory logs. Every click, every API call, every token — saved in excruciating detail. The Synapse paper did this. It’s like keeping a video recording of everything you did yesterday and expecting to learn life lessons from it. You get data, not insight.
Second camp: workflow summaries from successful runs only. Agent Workflow Memory does this. It’s better than raw logs, but it ignores the most valuable teacher — failure. If you only learn from wins, you never build any guardrails against the things that went wrong.
Both approaches miss the point. You don’t need a transcript of every action. You need the tactical reasoning behind why that action worked or didn’t.
What ReasoningBank actually does
ReasoningBank distills experiences into structured memory items. Each one has three parts:
- A title (short, descriptive)
- A description (brief summary)
- The actual content: distilled reasoning steps, decision rationales, or operational insights
Here’s where it gets clever. The system runs a continuous loop: retrieve relevant memories, interact with the environment, self-assess the trajectory using an LLM-as-a-judge, then extract new insights from both successes and failures.
That self-judgment piece is worth noting. The authors explicitly say it doesn’t need to be perfectly accurate — ReasoningBank is apparently robust against noise in the judgment. That’s a practical concession that I appreciate. In the real world, your evaluation signal is never clean.
But the real innovation is learning from failure. Instead of just recording “click ‘Load More’ button” as a workflow step, the agent might learn “always verify the current page identifier first to avoid infinite scroll traps before attempting to load more results.” That’s a generalizable reasoning pattern, not a scripted action.
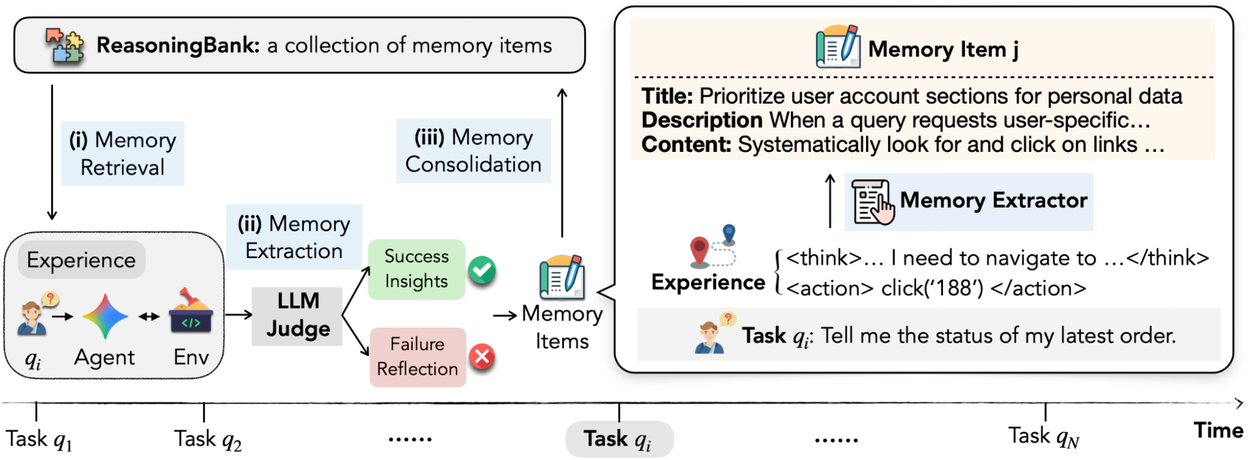
Workflow of ReasoningBank integrated with an agent during test time.
Does it actually work?
According to the paper, yes. On web browsing and software engineering benchmarks, ReasoningBank improved both success rates and efficiency (fewer steps per task) compared to baselines.
I’d want to see more independent replication before getting too excited, but the approach makes intuitive sense. Learning from failure is how humans actually get better at complex tasks. It’s weird that we’ve been building agents that don’t do this.
What I’d like to see next
The current implementation is straightforward — new memories just get appended to the bank. The authors acknowledge this is a simplification and leave “more sophisticated consolidation strategies for future work.” That’s fine for a research paper, but in practice, you’re going to end up with a lot of noise if every failure spawns a new memory item. Deduplication, pruning, and importance weighting would make this production-ready.
Also, the LLM-as-a-judge approach is convenient but introduces its own failure modes. If the judge is biased or lazy, the memories degrade. The paper claims robustness, but I’d want to stress-test that in longer-running deployments.
Still, this is one of the more practical agent memory papers I’ve seen in a while. It tackles a real bottleneck — the inability of deployed agents to improve over time — without over-engineering the solution.
Code is on GitHub if you want to poke around. I’ll be curious to see how this evolves.
Comments (0)
Login Log in to comment.
Be the first to comment!