
I’ve been following the user simulation space for a while now, and honestly, most approaches feel like they’re stuck in the uncanny valley. You know the vibe — an LLM pretending to be a frustrated user, but it’s way too patient, too verbose, and somehow knows every obscure detail about the product it’s supposedly shopping for. It’s like asking a chess grandmaster to lose on purpose; they can try, but it never looks quite right.
Google Research just dropped ConvApparel, and it’s the first serious attempt I’ve seen to quantify that weirdness. They’ve built a dataset and an evaluation framework that doesn’t just say “our simulator is good” — it actually measures how far off it is from real human behavior.
The realism gap is real
The problem is simple on the surface: LLMs are trained to be helpful. They’re polite, they remember context (mostly), and they don’t get annoyed when you ask the same question three times. Human users? Not so much. We forget what we said two turns ago, we get frustrated, we make contradictory requests, and we sometimes just ghost the conversation.
When you train a conversational agent against these overly polite simulators, you’re basically teaching it to handle a perfect world. Deploy it against actual users, and it falls apart. The paper calls this the “realism gap,” and it’s been a known issue for years, but nobody had a good way to measure it until now.
How ConvApparel works
Here’s the clever part: Google didn’t just collect a bunch of human-AI conversations. They set up a dual-agent system where real participants were randomly routed to either a helpful “Good” agent or an intentionally unhelpful “Bad” agent. This captures the full spectrum — from satisfied users to deeply annoyed ones. That’s way more useful than the typical dataset where everyone’s either neutral or mildly pleased.
They validated this with a three-pillar approach:
- Population-level statistics (do the simulators match overall human behavior patterns?)
- Human-likeness scoring (do individual responses feel human?)
- Counterfactual validation (can the simulator handle completely unexpected scenarios?)
That last one is the real innovation. Most simulators are trained on data from one specific agent, then tested against similar agents. That’s like training a pilot on clear skies and then testing them on clear skies. The real test is: what happens when the agent suddenly becomes terrible? Can the simulator adapt realistically?
Counterfactual validation matters more than you think
This is where I got excited. The paper introduces this concept of testing simulators against “out-of-distribution” assistant behavior — basically, throwing curveballs that the simulator’s training data never prepared it for.
Think about it: if you’re building a new conversational agent, you’re going to try novel policies. Maybe you’re testing a more aggressive upsell strategy, or a weird clarification flow. If your simulator just repeats patterns from its training data, it’s useless for evaluating these new approaches. You need a simulator that can react plausibly to things it’s never seen before.
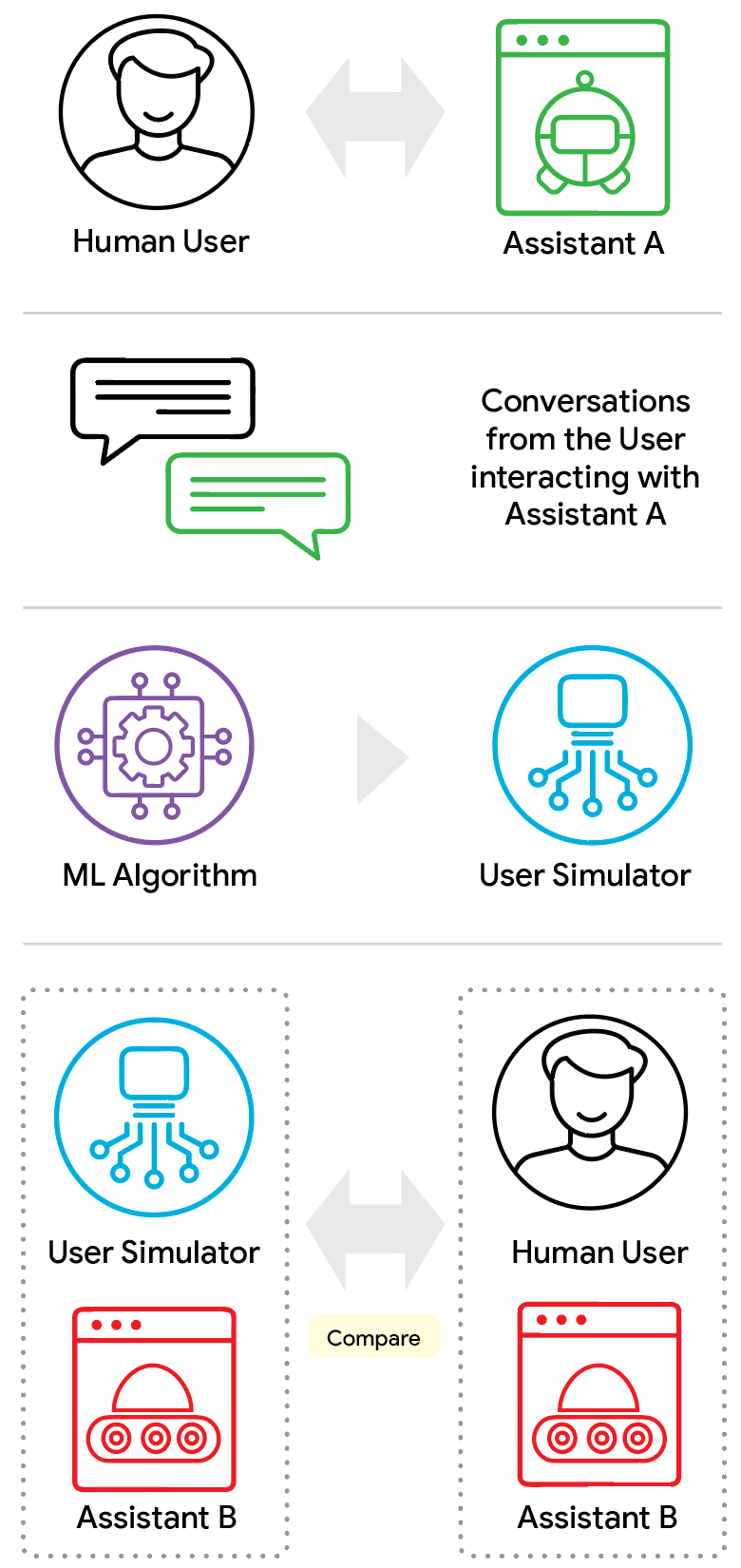
The diagram shows the idea: you train a simulator on human conversations with a “Good” agent, then test it against a “Bad” agent. If it just mimics the training data, it’ll behave like it’s talking to a helpful assistant even when the agent is being terrible. That’s a fail.
What this means for practitioners
If you’re building conversational AI, this is directly relevant. ConvApparel gives you a framework to:
- Quantify how realistic your simulator actually is
- Identify specific failure modes (too patient, too knowledgeable, etc.)
- Test whether improvements to your simulator actually close the gap
It’s not a silver bullet — the dataset focuses on conversational recommender systems, so it’s domain-specific. But the evaluation methodology is generalizable. I’d love to see this applied to customer support, healthcare, or even game NPCs.
One thing I wish they’d done differently: the paper is heavy on methodology but light on practical recommendations for fixing the realism gap once you’ve measured it. They show you how to spot the problem, but the “how to fix it” part feels a bit hand-wavy. Still, measuring is the first step, and this is a solid step.
The bottom line: if you’re using LLM-based user simulators and you haven’t validated them against real human behavior, you’re probably overestimating how good your conversational agent is. ConvApparel gives you the tools to stop guessing.
Comments (0)
Login Log in to comment.
Be the first to comment!